

Research
29 June 2026
Written by
the Flexion Team

1. Introducing Reflect v1.0, our Robotics Intelligence Platform for Long-Horizon Work
Humanoid robots are meant to carry out long-horizon autonomous missions in a world built for humans. This is hard. These missions consist of many steps, each of which requires them to perceive, navigate, and interact with the environment. This is exactly Flexion's goal: building the general-purpose intelligence that turns any robot into a useful helper.
Today, we are showing a significant step in that direction. The robot receives a single instruction:
"A parcel with snacks has been delivered for Flexion. Retrieve it using the stairs and come up using the elevator. Then unpack it and place the items into the empty drawer on the shelf in the snack area."
From there, everything is autonomous. No human operator is involved. The robot understands the instruction, locates the box in a dedicated area, and navigates a multi-floor building. During which it interacts with doors and elevators, uses tools to open the box, places its content on a shelf, and adapts when things don't go as planned, because in practice they never do.
Long-horizon autonomy is unforgiving. A navigation policy that works 95% of the time, a grasp that works 90% of the time, and a planner that occasionally misreads the scene do not combine into a reliable system. They compound into failure. To solve the challenge, we had to rethink the whole autonomy system from the ground up, from training our own vision-language model (VLM) agent to creating a new high-performance runtime architecture.
The significance of this result is not any single capability. It is that reasoning, perception, physical execution, and runtime robustness now compose into a mission-capable system.
We call the system behind it Reflect, our robotics intelligence platform.
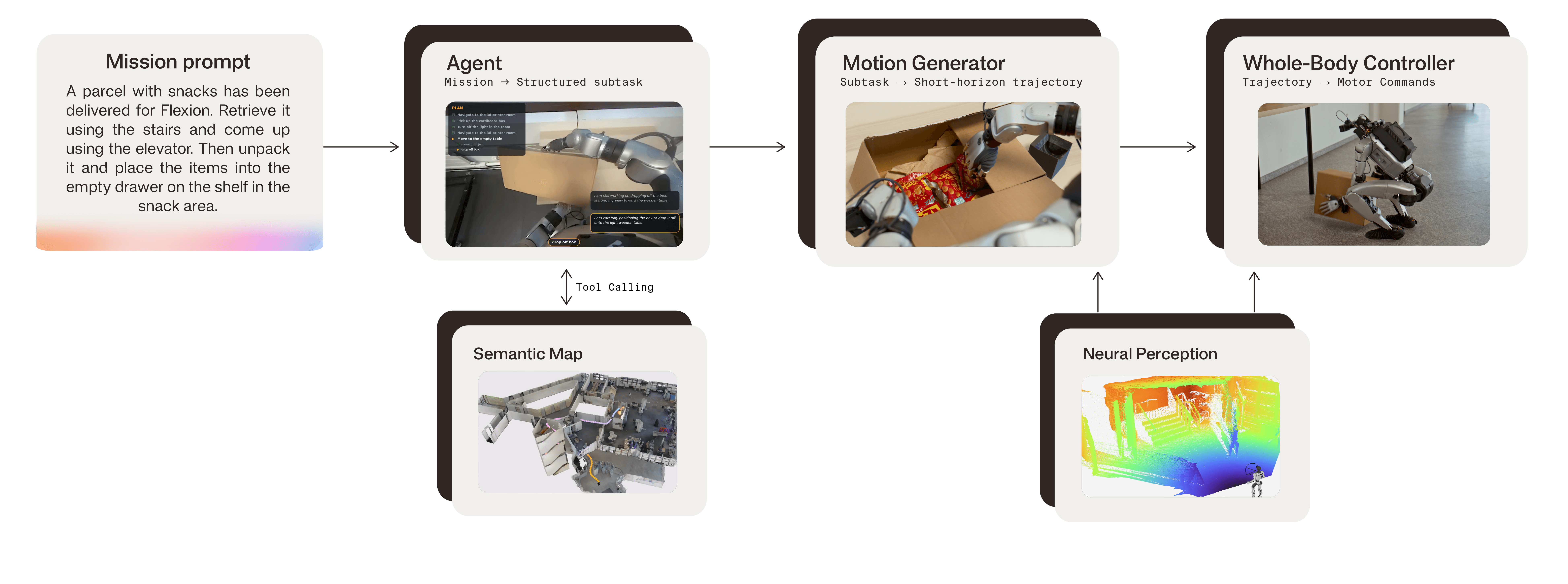
A custom VLM serves as mission control, reacting live, replanning continuously, and adapting as the mission unfolds.
Beneath it, a motion layer combines a VLA trained on real-world data with reinforcement learning (RL)-based skills. It translates what the robot sees into navigation, scene interaction, and manipulation commands.
A robust whole-body controller closes the loop in real time.
An optimized runtime handles everything else: communication, process isolation, low-latency inference, logging, and safety checks.
A few months ago, we shared the architecture of Reflect v0. Reflect v1.0 keeps the same overall design, however, the perception system is richer in semantics, the mission controller is smarter and more reactive, the motion layer is more capable, the controller is tighter, and the runtime is faster. The biggest shift in v1.0 is that RL is no longer confined to individual motion skills. We use it across every layer from low-level control to high-level decisions.
2. Mission-Level Reasoning with the Reflect-VLM
At the top of Reflect v1.0, the mission controller turns a high-level user instruction into a sequence of decisions. It observes the robot’s egocentric camera view, reasons about progress, and selects the next action through a set of structured tools.

Egocentric view of a mission with agent reasoning overlay.
Through the semantic map tool, the agent can reason over a language-grounded representation of the environment. From a scan of the building, we automatically generate a global map that supports natural language interaction, allowing the agent to query areas or objects from a text prompt and even request a global path to the target location. The user can further annotate the map with mission-critical landmarks and information.

The semantic map tool can be used by the agent to query locations and plan global paths using natural language.
Our VLM makes the system easy to reconfigure. The mission is specified directly in natural language, making task changes a matter of updating the prompt rather than modifying the code. In the following demonstrations, we showcase several task configurations in which only the user instruction changes.
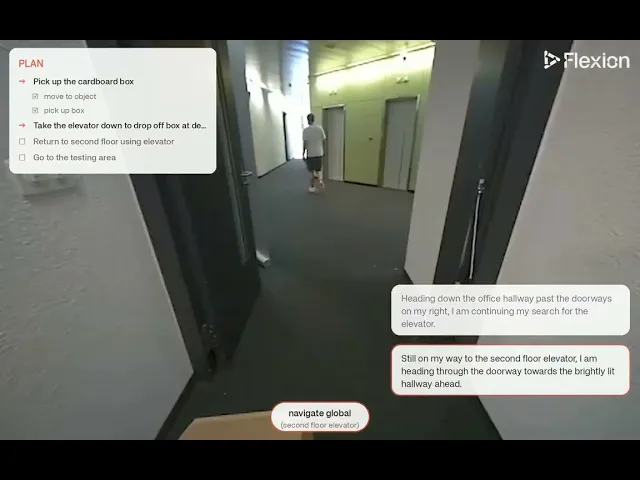
Mission variation using the prompt: "Pick up the cardboard box in the 3D printer room and drop it off in the delivery area on the ground floor by using the elevator. After the drop-off, come back up using the elevator to the second floor and then go to the testing area."
It is also possible to modify the mission on the fly. In the following video, the robot performs a mission, but it is interrupted mid-mission with updated instructions.
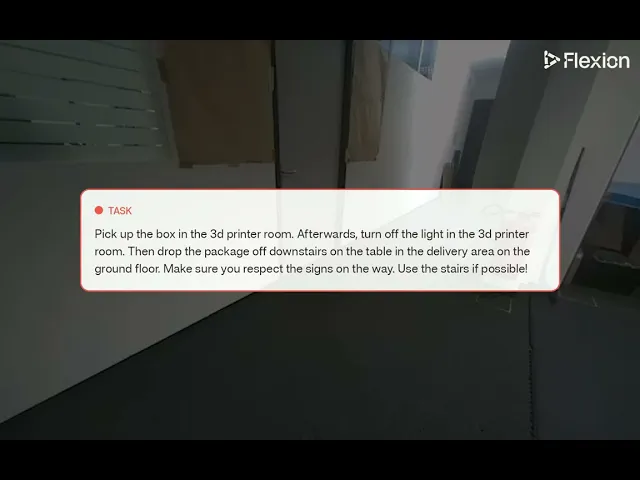
Mission variation using the prompt: "Pick up the box in the 3d printer room. Afterwards, turn off the light in the 3d printer room. Then drop the package off downstairs on the table in the delivery area on the ground floor. Make sure you respect the signs on the way. Use the stairs if possible!". During execution, the user interrupts and modifies the mission using the prompt: "Scratch that! Come back all the way to the testing area by going through the 3d printer room! Then, drop the box off on the empty table!"
Notably, we found that off-the-shelf VLMs are not reliable enough to drive complete missions out of the box. These models can identify objects and generate plausible instructions, though they often act too eagerly. Instead of visually verifying that the previous tool call has completed and that the scene satisfies the preconditions for the next step, they emit the next logically plausible tool call too quickly.
RL is key to the long-horizon reliability of Reflect v1.0. Supervised fine-tuning of pre-trained VLMs provides a useful starting point, yet it does not hold up when the robot must make decisions amid ambiguity, recover from failed attempts, and keep progressing when the plan diverges.

Long-horizon reliability improves only after RL fine-tuning. On a 16-step mission evaluation, SFT reaches 38% end-to-end completion, while SFT+RL reaches 90%.
To showcase this, we evaluate the mission controller on a 16-step mission from an evaluation set, measuring how far each rollout progresses before making its first mistake. The base VLM fails almost immediately, despite choosing the prompt carefully and giving it in-context examples. With supervised fine-tuning (SFT), the first signs of success begin to emerge, reaching 38% success rate with end-to-end completion, but errors still accumulate over time. With RL fine-tuning, completion rises to 90%.
3. From Pixels to Physical Interaction
Below the agent, the motion layer turns decisions into physical interactions, e.g., to open a door, call the elevator, or navigate the environment.
Most skills are trained in simulation with custom visual encoders and targeted domain randomization. Perceptive feedback is required to adapt the motion online, because the robot cannot assume a perfectly arranged scene. Objects can appear in different poses, and the robot may arrive from an awkward configuration after walking, turning, or recovering. RL lets us train for this diversity by exposing the policy to a broad distribution of scenarios until it becomes robust to the variation it will encounter in the real world.
Contact-Rich Whole-Body Interaction
Contact-rich skills are where small differences matter most. A door handle is not always at the same height, a box can have a different size, weight, friction, and can even deform. A policy that works only for a single geometry or a single initial condition will ultimately result in mission failure.
Box pickup
In the following video, we show the full adaptability of our high-level policy to different conditions.

The same policy can pickup a variety of boxes, with weights varying from 100 g to 3.5 kg.
Box repositioning
After the box is picked up, it is repositioned under one arm to free the other. This requires coordinated full-body control and would be very difficult to teleoperate.
Elevator
Elevators sit at an interesting boundary between symbolic and continuous control. "Press the elevator button" is a high-level instruction. Executing it requires identifying the correct button, moving into a stable whole-body interaction pose, and reaching with centimeter-level precision.
Dexterous manipulation
Tool use is second nature to humans, though dexterous manipulation remains one of the hardest problems in humanoid robotics. The hand needs to make contact with objects whose geometry is only partially observed, and the controller must maintain balance while the upper body interacts with the world.
For this mission, we use a VLA trained on teleoperated data with our whole-body controller in the loop. We found that achieving high reliability in such settings is difficult, especially for a free-moving humanoid rather than a fixed-base manipulation system. We are already working on the next logical solution: solving these tasks with RL.
Local Navigation on Uneven Terrain
A robot that plans once and then executes blindly will eventually get stuck. Reflect v1.0 combines global path planning with continuous local adaptation, allowing the robot to adjust and keep moving when something unexpected appears in its path.

The robot can avoid dynamic obstacles while carrying items.

The robot can avoid obstacles on rough terrain.
4. Whole-Body Control Under Real Task Constraints
Everything above depends on the quality of control. The most sophisticated mission reasoning does not matter if the robot can't track commanded motions accurately, maintain balance while carrying a box, or recover from a disturbance mid-manipulation. Whole-body control makes the rest of Reflect possible. Reflect v1.0's controller runs in real time, simultaneously respecting balance, actuation limits, and safety constraints. It stays stable when the upper body is manipulating, when the terrain is uneven, and when the task demands change faster than any high-level planner can anticipate. Robustness is the key focus. The robot can now perform 100+ stair traversals in a row and manipulate objects under significant disturbances.

The policy repeatedly walks up and down stairs without falling.

The robot is able to keep balance without compromising tracking performance, even with external disturbances.
We call this low-level control module Reflex, capable of performing advanced locomotion and force-aware whole-body control. It can be trained for and deployed on different robots and morphologies with minimal human effort.
5. Robustness and Retry
Failures are inevitable during execution. A box slips. A grasp is missed. A previously valid plan becomes invalid. Reflect v1.0 handles this at multiple levels:
The motion layer can handle execution failures locally, using recovery behaviors learned during RL training.

The policy tries to pick up a box that is out of distribution, initially fails, attempts again, and then succeeds.

The policy adjusts locally when the box is pushed away.
The agent replans when a subgoal fails by detecting off-nominal situations directly from the camera feed.

The VLM monitors progress based on the camera feed. It detects off-nominal situations and replans accordingly.
This kind of recovery is critical for a deployable robot system. In real environments, success rarely comes from executing a perfect plan once; it comes from detecting when execution has drifted, recovering locally when possible, and escalating to replanning when necessary.
6. Rethinking the Software Stack
To make Reflect v1.0 production-ready, we needed to rethink the deployment runtime from the ground up. We abstracted all the interfaces of Reflect v1.0, making it easy to integrate on any hardware platform. Additionally, readily available robotic libraries didn't offer the performance and flexibility we needed. Dozens of devices (Jetsons, sensors, motors, servers, etc.) are involved in the deployment of Reflect v1.0, which means that Gigabytes of data are sent every second between the different components. So we built FlexComm:
Fast: minimal delays (tens to hundreds of microseconds) for same-host communication, with a speed-up of up to 40% over ROS DDS.
Efficient: 30% CPU improvement compared to ROS2 DDS.
Reliable: resilient against network disruptions (for example, WiFi roaming or disconnects).
Scalable: onboard compute units, workstations, and even cloud instances can be linked while reducing the risk of accidental cross-talk between different robots.
Another key challenge in complex robot deployments is observability, i.e., identifying and diagnosing problems with any part of Reflect v1.0 or any of the devices and connections of the robot. Even a 1% chance of failure of each component would cause frequent failures of the overall system. Our monitoring platform automatically collects diagnostics at all levels, from reasoning traces to kernel and network interface logs, surfaces them live to the operator, and stores them for future analysis.
Finally, developing a complex intelligence platform is only possible if the entire system can be tested efficiently. For this purpose, we are also building a photorealistic simulation pipeline based on 3D Gaussian splatting. The simulator has to (i) produce observations realistic enough for the VLM and perception models, (ii) model geometry accurately enough for our low and high-level policies to function, (iii) run fast enough to keep the loops running at realistic rates, and (iv) let us inspect every decision when something fails. This way, we can test more missions, compare model variants faster, and identify failure modes earlier in the development cycle.

Example roll-out of Reflect v1.0 in simulation. We run the full pipeline before deploying on the real robot to detect any issues.
Building our intelligence capabilities within a scalable, flexible, and performant infrastructure is an investment that is invisible compared to our intelligence capabilities. But it unlocks production-grade, long-horizon autonomy.
7. Limitations
While Reflect v1.0 is an important step in bringing humanoids closer to real-world deployment, it does not completely solve humanoid autonomy.
The current system still operates within a bounded task distribution. The skills shown here are robust to meaningful variation; however, they are not universal. Some objects remain difficult to grasp. The mission controller can still make incorrect assumptions from visual input. Recovery behaviors work for some failure modes but not all.
We view these limitations as data. They show us where to scale next: broader skill distributions, better failure detection and recovery, stronger sim evaluation, tighter runtime budgets, and more general mission reasoning trained end-to-end from verifiable rewards.
8. Conclusion
Reflect v1.0 brings several hard robotic capabilities into a single working system: perceptive environment interaction, robust whole-body control, mission-level reasoning, recovery, and an onboard runtime that can support all of it. The presented mission is an important milestone for us because these components are no longer evaluated only as isolated clips. They can now be composed into a system that acts through time, interacts with the world, changes its plan, and continues to make progress under real constraints.
This gives us a foundation we can build on, where every new mission can start from a stronger foundation than the last. Most of our skills are trained using reinforcement learning in simulation, which makes it easier to scale behaviors, adapt them across embodiments, and move to new robots without rebuilding everything from scratch. In parallel, we are building a skill factory that shortens the path from task definition to deployed behavior. As this matures, new tasks become part of a growing system of capabilities.
The same loop exists at the mission level. Each new mission gives the VLM agent more evaluation signals, broader coverage of failure modes, and more examples of how plans succeed or fail in the real world. The agent improves, the skill factory gets faster, the controller becomes more reusable, and the runtime makes the whole system easier to debug and extend.
That compounding is what we care about, because it sets the path to Flexion-powered robots deployed in real world settings.
Written by
the Flexion Team



