

Research
20 November 2025
Written by
the Flexion Team
Introduction
Training robots with data collected manually for every possible scenario is a dead end. The real world is far too rich and unpredictable: every object, every surface, every motion multiplies the number of potential edge cases. Luckily, we don’t have to brute-force it. Instead of attempting to teach a robot every possible sequence of actions, we can give it access to a toolbox of reusable skills, each trained for reliability, and then orchestrate them with foundation models that understand the world.
Recent works from SayCan and RT-2 to MolmoAct and ThinkAct demonstrate that language models can decompose tasks by leveraging both text and perception, while sim-to-real research has shown that low-level skills can be learned robustly in simulation and transferred to hardware. Building on these ideas, our bet at Flexion is on the following architecture:
LLM/VLM agent for task scheduling & common sense. It decomposes goals, selects tools, and understands everyday conventions. Desirable outcomes can be programmed via prompting and fine-tuning.
General motion generator. Given images, 3D perception, and an LLM-produced task instruction, it proposes short-horizon, collision-aware local trajectories, e.g., to move the end-effector to grasp a box or for the full body to navigate.
RL-based whole-body tracker. It executes commands robustly across all terrain types and different command spaces.
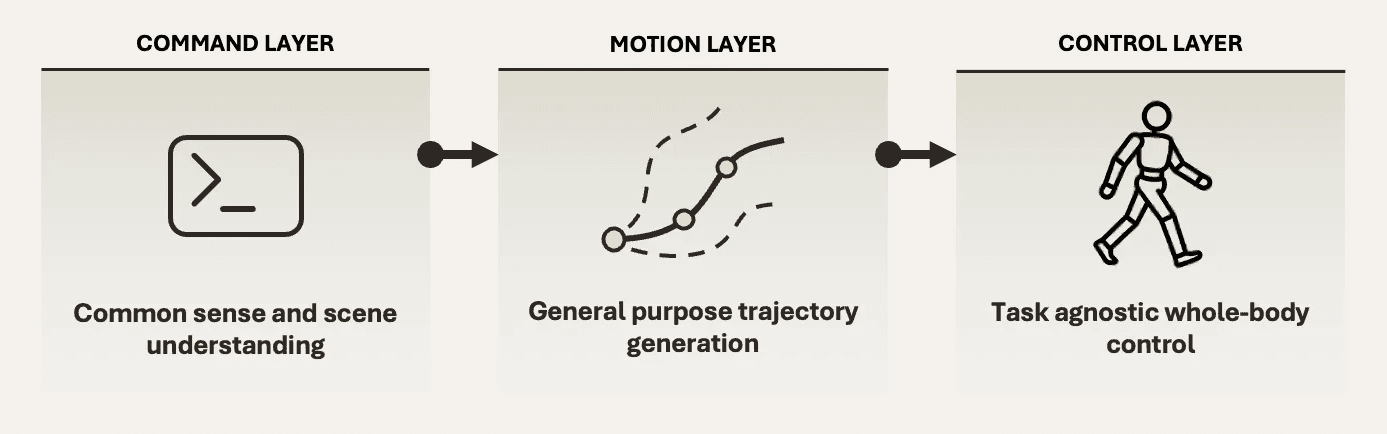
This modularity avoids brittle end-to-end monoliths and improves generalization by keeping interfaces clean and testable. Importantly, our data strategy is asymmetric: we leverage simulation and synthetic data wherever possible, and selectively incorporate real data when it closes specific gaps. This aligns with the trajectory of large, diverse robot datasets (e.g., Open-X Embodiment, RT-X) and prompt-driven manipulation research (e.g., VIMA), showing that breadth helps planning and perception. At the same time, control stays grounded in physically faithful training.
Results
Working towards this paradigm, we begin with a long-horizon task: tidying up a space by picking up the toys and putting them in a basket.
Despite its apparent simplicity, this task stresses every level of the autonomy stack from perception and state estimation to locomotion, manipulation, and planning. The robot must detect scattered and previously unseen objects, plan a path across uneven terrain, approach each target safely, coordinate its body to grasp the objects, and finally drop them off at the correct location.
In our current implementation, the LLM agent orchestrates the task by invoking available skills through tool calls. No hardcoded state machine or teleoperation is involved: the entire sequence emerges from the agent’s reasoning.
Method
Our system combines independently trained motor skills, higher-level behaviors, and an LLM-based decision-making agent. Each layer operates within a clearly defined scope: robust control at the bottom, compositional reasoning at the top. Although the skills are currently separate, they are designed to evolve into core building blocks of the whole-body tracker and motion generator.
Motor skills
At the foundation lie our reinforcement learning–based motor skills, which are trained entirely in simulation through massive randomization and perturbations.
Perceptive rough terrain locomotion
Trained across a wide distribution of surfaces and conditions, and subjected to dynamic disturbances such as external pushes, sensor delays, and changes in ground friction. The resulting controller can maintain balance and recover gracefully from unexpected slips. It leverages its exteroceptive sensors to make informed decisions about foot placement.

Whole-body end-effector tracking
A specialized controller for whole-body coordination and end-effector tracking. The pelvis’ height and the hands’ target poses can be commanded independently, allowing the robot to grasp objects at varying heights. This can also be deployed interactively through teleoperation, as illustrated in the following example.

Higher-level skills
On top of the motor control layer, we define reusable skills that encapsulate motion primitives into higher-level behaviors.
Navigation
Robust goal-reaching behavior: the robot can move from point A to point B while compensating for terrain irregularities and localization noise. It can reach a position with sufficient accuracy to enable a successful grasp.
Object pick-up
Combines end-effector tracking and grasp control to fetch detected objects. Grasp parameters are conditioned on object geometry, stability, and reachability.

Agent
At the top of the hierarchy, the VLM agent serves as the interface between high-level intent and executable robot skills.
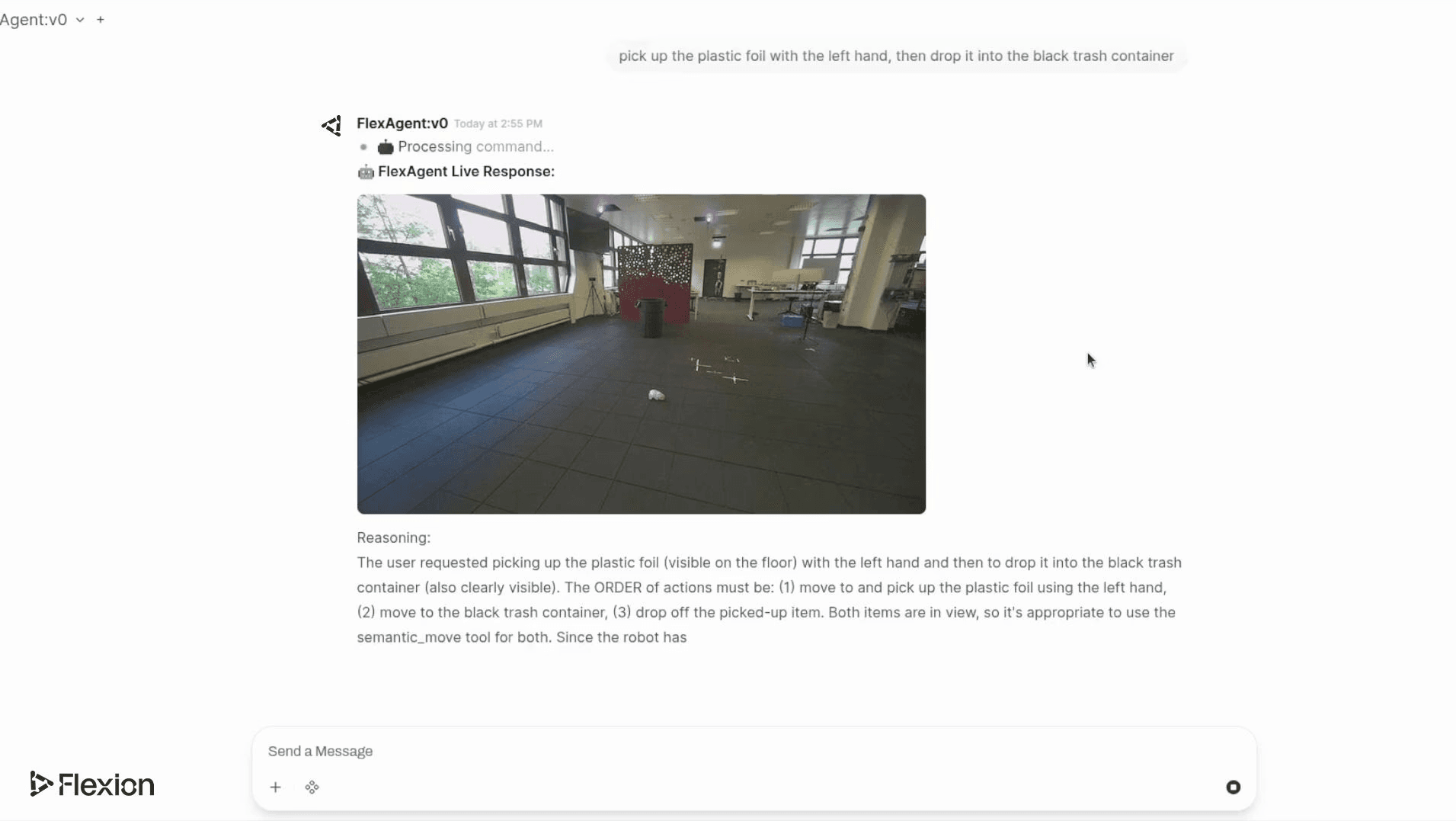
Given a user prompt such as “Pick up the toys and place them into the basket”, the agent decomposes the task into atomic actions, selects the appropriate tools, and sequences them coherently.
Internally, it uses a combination of language reasoning and visual grounding to maintain context:
Perception integration
The agent leverages open vocabulary-based segmentation to identify relevant objects from visual input. These detections are continuously tracked and anchored in 3D, providing persistent world references.
Tool orchestration
Actions are executed via callable APIs to detect objects, move to a target location, pick up and drop off items, with the LLM determining when and how to call each based on scene understanding and task progress.
This architecture cleanly separates what the robot should do from how it should do it. The result is a control stack in which language drives intent and physics enforces feasibility.
Hardware integration
Our current setup combines on-board control with cloud-based reasoning.
An Nvidia Jetson Orin module, mounted in a custom backpack, enables the robot to run both low-level and high-level control loops, motion estimation, and 3D scene understanding. The onboard system receives commands from the cloud-hosted VLM agent and converts them into joint-space actions. A ZED stereo camera mounted at the front of the robot provides RGB-D sensing, enabling the agent to detect objects and precisely anchor them in 3D space for spatial reasoning and task planning.
This hybrid setup keeps latency-critical control local while leveraging scalable cloud resources for non-safety-critical reasoning. The modular design makes our autonomy stack platform-agnostic, and we are already validating it across different robotic platforms. In future iterations, the backpack will be upgraded with a Jetson Thor, enabling full on-board reasoning for completely self-contained autonomy.

Outlook
This is only the beginning, the first application of our modular autonomy stack.
Looking ahead, our roadmap focuses on expanding capability, scalability, and generality:
Next-generation whole-body control
A unified, transformer-based policy capable of traversing any terrain while following diverse, multi-modal commands, from navigation goals to manipulation intents.
Motion generator
Integrating our diffusion-based motion generator that predicts short-horizon, physically consistent trajectories directly from visual input and task context. This module enables interaction-rich behaviors, such as opening doors, picking and placing totes, or manipulating articulated objects, thereby bridging high-level intent from the agent with precise motion proposals.
Spatial intelligence
Map-aware reasoning that enables the agent to understand and plan within 3D space, both locally and globally.
End-to-end agent fine-tuning
Specializing the VLM agent on robot-specific APIs and task distributions to improve grounding, reduce ambiguity, and enable longer-horizon planning. To accelerate learning, the agent will be deployed in simulated worlds.
Together, these steps move us closer to a general-purpose humanoid brain, one that can reason broadly, move gracefully, and adapt to real-world complexity with minimal human involvement.
Written by
the Flexion Team



